Interested in the theory of point processes? There is the freely available online book manuscript:
Baccelli, Błaszczyszyn, and Karray – Random Measures, Point Processes, and Stochastic Geometry.
The authors are established names in the field having written many papers on using point processes to model wireless networks.
(Disclaimer: I have worked and published with them. I have even co-authored a book with one of them.)
Of course there are already books on point process, including the two-volume classic by the Daryl Daley and David Vere-Jones. Although that work still serves as a good reference, since its publication researchers have produced many new results. This explains the publication of two more recent books on point processes and their generalization random measures:
Last and Penrose – Lectures on the Poisson process, Cambridge University Press.
Kallenberg – Random Measures, Theory and Applications, Springer.
There’s a free online version of the book by Last and Penrose.
(Disclaimer: Günter Last graciously mentioned my name in the acknowledgements for my very minor contribution to the historical section.)
The manuscript by Baccelli, Błaszczyszyn, and Karray covers newer topics and results by using mathematically rigorous proofs. For example, there are interesting results on determinantal point processes, also called fermion point processes, which started off as a model for subatomic particles in seminal work by Odile Macchi, but they have found applications in wireless network models and machine learning. (I mentioned these later applications in this and this post.)
Despite applications being a strong motivation, the book is not for the faint of hearted in terms of mathematics. In the tradition of French probability, there is plenty of rigour, which means mathematical abstraction, analysis and measure theory.
Update: Mohamed Karray uploaded some lecture slides based on these lectures. Karray is a researcher at Orange Labs in Paris who has research interests in telecommunications (naturally), as well as machine (or statistical) learning.
Further reading
Classic books
Anyone who wants to learn anything about the Poisson point process must consult this gem of mathematical writing:
Kingman – Poisson Processes, Oxford Press.
The next volumes were the standard reference on point processes:
Daley and Vere-Jones – An Introduction to the Theory of Point Processes: Volume I: Elementary theory and Methods, Springer.
Daley and Vere-Jones – An Introduction to the Theory of Point Processes: Volume II: General theory and Structure, Springer.
Unfortunately, some of the methods are dated and, I am told, there some flaws in some of the mathematical proofs. Still, it has packed full of results and references, serving as a good starting point.
Recent books
As I mentioned above, these two recent books cover the modern theory of point processes:
Last and Penrose – Lectures on the Poisson process, Cambridge University Press.
Kallenberg – Random Measures, Theory and Applications, Springer.
Determinantal point processes
The applications of determinantal point processes stem from their tractable mathematical properties, some of which were proved by researchers Takahashi and Shirai in the two papers:
2003 – Takahasi and Shirai – Random point fields associated with certain Fredholm determinants I: fermion, Poisson and boson point processes, Journal of Functional Analysis.
2003 – Takahasi and Shirai – Random point fields associated with certain Fredholm determinants II: fermion shifts and their ergodic and Gibbs properties, Annals of Applied Analysis.
Another important paper on these point processes is
One of the most important stochastic processes is Poisson stochastic process, often called simply the Poisson process. In a previous post I gave the definition of a stochastic process (also called a random process) alongside some examples of this important random object, including counting processes. The Poisson (stochastic) process is a counting process. This continuous-time stochastic process is a highly studied and used object. It plays a key role in different probability fields, particularly those focused on stochastic processes such as stochastic calculus (with jumps) and the theories of Markov processes, queueing, point processes (on the real line), and Levy processes.
The points in time when a Poisson stochastic process increases form a Poisson point process on the real line. In this setting the stochastic process and the point process can be considered two interpretations of the same random object. The Poisson point process is often just called the Poisson process, but a Poisson point process can be defined on more generals spaces. In some literature, such as the theory of Lévy processes, a Poisson point process is called a Poisson random measure, differentiating the Poisson point process from the Poisson stochastic process. Due to the connection with the Poisson distribution, the two mathematical objects are named after Simeon Poisson, but he never studied these random objects.
The other important stochastic process is the Wiener process or Brownian (motion process), which I cover in another post. The Wiener process is arguably the most important stochastic process. I have written that post and the current one with the same structure and style, reflecting and emphasizing the similarities between these two fundamental stochastic process.
In this post I will give a definition of the homogenous Poisson process. I will also describe some of its key properties and importance. In future posts I will cover the history and generalizations of this stochastic process.
Definition
In the stochastic processes literature there are different definitions of the Poisson process. These depend on the settings such as the level of mathematical rigour. I give a mathematical definition which captures the main characteristics of this stochastic process.
Definition: Homogeneous Poisson (stochastic) process
An integer-valued stochastic process \(\{N_t:t\geq 0 \}\) defined on a probability space \((\Omega,\mathcal{A},\mathbb{P})\) is a homogeneous Poisson (stochastic) process if it has the following properties:
The initial value of the stochastic process \(\{N_t:t\geq 0 \}\) is zero with probability one, meaning \(P(N_0=0)=1\).
The increment \(N_t-N_s\) is independent of the past, that is, \(N_u\), where \(0\leq u\leq s\).
The increment \(N_t-N_s\) is a Poisson variable with mean \(\lambda (t-s)\).
In some literature, the initial value of the stochastic process may not be given. Alternatively, it is simply stated as \(N_0=0\) instead of the more precise (probabilistic) statement given above.
Also, some definitions of this stochastic process include an extra property or two. For example, from the above definition, we can infer that increments of the homogeneous Poisson process are stationary due to the properties of the Poisson distribution. But a definition may include something like the following property, which explicitly states that this stochastic process is stationary.
For \(0\leq u\leq s\), the increment \(N_t-N_s\) is equal in distribution to \(N_{t-s}\).
The definitions may also describe the continuity of the realizations of the stochastic process, known as sample paths, which we will cover in the next section.
It’s interesting to compare these defining properties with the corresponding ones of the standard Wiener stochastic process. Both stochastic processes build upon divisible probability distributions. Using this property, Lévy processes generalize these two stochastic processes.
Properties
The definition of the Poisson (stochastic) process means that it has stationary and independent increments. These are arguably the most important properties as they lead to the great tractability of this stochastic process. The increments are Poisson random variables, implying they can have only positive (integer) values.
The Poisson (stochastic) process exhibits closure properties, meaning you apply certain operations, you get another Poisson (stochastic) process. For example, if we sum two independent Poisson processes \(X= \{X_t:t\geq 0 \}\) and \(Y= \{Y_t:t\geq 0 \}\), then the resulting stochastic process \(Z=Z+Y = \{N_t:t\geq 0 \}\) is also a Poisson (stochastic) process. Such properties are useful for proving mathematical results.
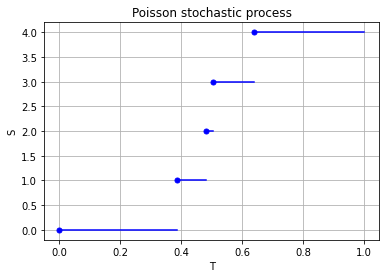
A single realization of a (homogeneous) Poisson stochastic process, where the blue marks show where the process jumps to the next value. In any finite time interval, there are a finite number of jumps.
Properties such as independence and stationarity of the increments are so-called distributional properties. But the sample paths of this stochastic process are also interesting. A sample path of a Poisson stochastic process is almost surely non-decreasing, being constant except for jumps of size one. (The term almost surely comes from measure theory, but it means with probability one.) There are only finitely number of jumps in each finite time interval.
The homogeneous Poisson (stochastic) process has the Markov property, making it an example of a Markov process. The homogenous Poisson process \(N=\{ N_t\}_{t\geq 0}\)s not a martingale. But interestingly, the stochastic process is \(\{ W_t – \lambda t\}_{t\geq 0}\) is a martingale. (Such relations have been used to study such stochastic processes with tools from martingale theory.)
Stochastic or point process?
The Poisson (stochastic) process is a discrete-valued stochastic process in continuous time. The relation these types of stochastic processes and point process is a subtle one. For example, David Cox and Valerie Isham write on page 3 of their monograph:
The borderline between point processes and a number of other kinds of stochastic process is not sharply defined. In particular, any stochastic process in continuous time in which the sample paths are step functions, and therefore any any process with a discrete state space, is associated with a point process, where a point is a time of transition or, more generally, a time of entry into a pre-assigned state or set of states. Whether it is useful to look at a particular process in this way depends on the purpose of the analysis.
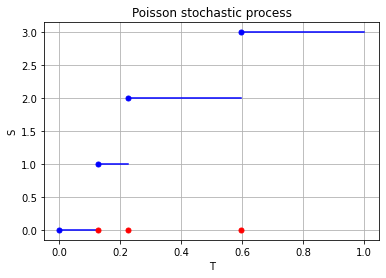
For the Poisson case, this association is presented in the diagram below. We can see the Poisson point process (in red) associated with the Poisson (stochastic) process (in blue) by simply looking at the time points where jumps occur.
A single realization of a (homogeneous) Poisson stochastic process (in blue). The jumps of the process form a (homogeneous) Poisson point process (in red) on the real line representing time.
Importance
Playing a prominent role in the theory of probability, the Poisson (stochastic) process is a highly important and studied stochastic process. It has connections to other stochastic processes and is central in queueing theory and random measures.
The Poisson process is a building block for more complex continuous-time Markov processes with discrete state spaces, which are used as mathematical models. It is also essential in the study of jump processes and subordinators.
The Poisson (stochastic) process is a member of some important families of stochastic processes, including Markov processes, Lévy processes, and birth-death processes. This stochastic process also has many applications. For example, it plays a central role in quantitative finance. It is also used in the physical sciences as well as some branches of social sciences, as a mathematical model for various random phenomena.
Generalizations and modifications
For the Poisson (stochastic) process, the index set and state space are respectively the non-negative numbers and counting numbers, that is \(T=[0,\infty)\) and \(S=0, 1, \dots\), so it has a continuous index set but a discrete state space. Consequently, changing the state space, index set, or both offers an ways for generalizing and modifying the Poisson (stochastic) process.
Simulation
The defining properties of the Poisson stochastic process, namely independence and stationarity of increments, results in it being easy to simulate. The Poisson stochastic process can be simulated provided random variables can be simulated or sampled according to a Poisson distributions, which I have covered in this and this post.
Simulating a Poisson stochastic process is similar to simulating a Poisson point process. (Basically, it is the same method in a one-dimensional setting.) But I will leave the details of sampling this stochastic process for another post.
A very quick history of Wiener process and the Poisson (point and stochastic) process is covered in this talk by me.
In terms of books, the Poisson process has not received as much attention as the Wiener process, which is typically just called the Brownian (motion) process. That said, any book covering queueing theory will cover the Poisson (stochastic) process.
More advanced readers can read about the Poisson (stochastic) process, the Wiener (or Brownian (motion)) process, and other Lévy processes:
The binomial point process is arguably the simplest point process. It consists of a non-random number of points scattered randomly and independently over some bounded region of space. In this post I will describe the binomial point process, how it leads to the Poisson point process, and its historical role as stars in the sky.
The binomial point process is an important stepping stone in the theory of point process. But I stress that for mathematical models, I would always use a Poisson point process instead of a binomial one. The only exception would be if you were developing a model for a small, non-random number of points.
Uniform binomial point process
We start with the simplest binomial point process, which has uniformly located points. (I described simulating this point process in an early post. The code is here.)
Definition
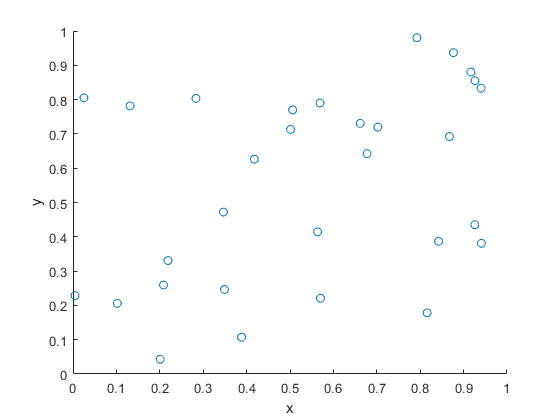
Consider some bounded (or more precisely, compact) region, say, \(W\), of the plane plane \(\mathbb{R}^2\), but the space can be more general. The uniform binomial point process is created by scattering \(n\) points uniformly and independently across the set \(W\).
A single realization of a binomial point process with n=30 points. The points are uniformly and independently scattered across a unit square.
Distribution
Consider a single point uniformly scattered in the region \(W\), giving a binomial point process with \(n=1\). We look at some region \(B\), which is a subset of \(W\), implying \(B\subseteq W\). What is the probability that the single point \(X\) falls in region \(B\)?
First we write \(\nu(W)\) and \(\nu(B)\) to denote the respective areas (or more precisely, Lebesgue measures) of the regions \(W\) and \(B\), hence \(\nu(B)\leq \nu(W)\). Then this probability, say, \(p\), is simply the ratio of the two areas, giving
$$p= P(X\in B)=\frac{\nu(B)}{\nu(W)}.$$
The event of a single point being found in the set \(B\) is a single Bernoulli trial, like flipping a single coin. But if there are \(n\) points, then there are \(n\) Bernoulli trials, which bring us to the binomial distribution.
For a uniform binomial point process \(N_W\), the number of randomly located points being found in a region \(B\) is a binomial random variable, say, \(N_W(B)\), with probability parameter \(p=\nu(B)/ \nu(W)\). The probability mass function of \(N_W(B)\) is
A standard exercise in introductory probability is deriving the Poisson distribution by taking the limit of the binomial distribution. This is done by sending \(n\) (the total number of Bernoulli trials) to infinity while keeping the binomial mean \(\mu:=p n\) fixed, which sends the probability \(p=\mu/n\) to zero.
More precisely, for \(\mu\geq0\), setting \(p_n=\mu/n \) and keeping \(\mu :=p_n n\) fixed, we have the limit result
We can make the same limit argument with the binomial point process.
Homogeneous Poisson point process
We consider the intensity of the uniform binomial point process, which is the average number of points in a unit area. For a binomial point process, this is simply
$$\lambda := \frac{n}{\nu(W)}.$$
For the Poisson limit, we expand the region \(W\) so it covers the whole plane \(\mathbb{R}^2\), while keeping the intensity \(\lambda = n/\nu(W)\) fixed. This means that the area \(\nu(W)\) approaches infinity while the probability \(p=\nu(B)/\nu(W)\) goes to zero. Then in the limit we arrive at the homogeneous Poisson point process \(N\) with intensity \(\lambda\).
The number of points of \(N\) falling in the set \(B\) is a random variable \(N(B)\) with the probability mass function
Typically in point process literature, one first encounters the uniform binomial point process. But we can generalize it so the points are distributed according to some general distribution.
Definition
We write \(\Lambda\) to denote a non-negative Radon measure on \(W\), meaning \(\Lambda(W)< \infty\) and \(\Lambda(B)\geq 0\) for all (measurable) sets \(B\subseteq W\). We can also assume a more general space for the underlying space such as a compact metric space, which is (Borel) measurable. But the intuition still works for compact region of the plane \(\mathbb{R}^2\).
For the \(n\) points, we assume each point is distributed according to the probability measure
$$\bar{\Lambda}= \frac{\Lambda}{\Lambda(W)}.$$
The resulting point process is a general binomial point process. The proofs for this point process remain essentially the same, replacing the Lebesgue measure \(\nu\), such as area or volume, with the non-negative measure \(\Lambda\).
Example
A typical example of the intensity measure \(\Lambda\) has the form
$$\Lambda(B)= \int_B f(x) dx\,,$$
where \(f\) is a non-negative density function on \(W\). Then the probability density of a single point is
$$ p(x) = \frac{1}{c}f(x),$$
where \(c\) is a normalization constant
$$c= \int_W f(x) dx\,.$$
On a set \(W \subseteq \mathbb{R}^2\) using Cartesian coordinates, a specific example of the density \(f\) is
$$ f(x_1,x_2) = \lambda e^{-(x_1^2+x_2^2)}.$$
Distribution
Assuming a general binomial point process \(N_W\) on \(W\), we can use the previous arguments to obtain the binomial distribution
We can easily adapt the Poisson limit arguments for the general binomial Poisson point process, which results in the general Poisson point process \(N\) with intensity measure \(\Lambda\). The number of points of \(N\) falling in the set \(B\) is a random variable \(N(B)\) with the probability mass function
The uniform binomial point process is an example of a spatial point process. With points being scattered uniformly and independently, its sheer simplicity makes it a natural choice for an early spatial model. But which scattered objects?
Perhaps not surprisingly, it is trying to understand star locations where we find the earliest known example of somebody describing something like a random point process. In 1767 in England John Michell wrote:
what it is probable would have been the least apparent distance of any two or more stars, any where in the whole heavens, upon the supposition that they had been scattered by mere chance, as it might happen
As an example, Michelle studied the six brightest stars in the Pleiades star cluster. He concluded the stars were not scattered by mere chance. Of course “scattered by mere chance” is not very precise in today’s probability language, but we can make the reasonable assumption that Michell meant the points were uniformly and independently scattered.
Years later in 1860 Simon Newcomb examined Michell’s problem, motivating him to derive the Poisson distribution as the limit of the binomial distribution. Newcomb also studied star locations. Stephen Stigler considers this as the first example of applying the Poisson distribution to real data, pre-dating the famous work by Ladislaus Bortkiewicz who studied rare events such as deaths from horse kicks. We also owe Bortkiewicz the terms Poisson distribution and stochastic (in the sense of random).
Code
Here, on my repository, are some pieces of code that simulate a uniform binomial point process on a rectangle.
Further reading
For an introduction to spatial statistics, I suggest the lectures notes by Baddeley, which form Chapter 1 of these published lectures, edited by Baddeley, Bárány, Schneider, and Weil. The binomial point process is covered in Section 1.3.
The binomial point process is also covered briefly in the classic text Stochastic Geometry and its Applications by Chiu, Stoyan, Kendall and Mecke; see Section 2.2. Similar material is covered in the book’s previous edition by Stoyan, Kendall and Mecke.
Haenggi also wrote a readable introductory book called Stochastic Geometry for Wireless networks, where he gives the basics of point process theory. The binomial point process is covered in Section 2.4.4.
For some history on point processes and the Poisson distribution, I suggest starting with the respective papers:
Guttorp and Thorarinsdottir, What Happened to Discrete Chaos, the Quenouille Process, and the Sharp Markov Property?;
Stigler, Poisson on the Poisson distribution.
Histories of the Poisson distribution and the Poisson point process are found in the books:
Haight, Handbook of the Poisson Distribution, Chapter 9;
Here’s a lazy summary post where I list all the posts on various Poisson simulations. I’ve also linked to code, which is found on this online repository. The code is typically written in MATLAB and Python.
In the previous post I outlined how to simulate or sample a homogeneous Poisson point process on the surface of a sphere. Now I will consider a homogeneous Poisson point process on the \((n-1)-\) sphere, which is the surface of the Euclidean ball in \(n\) dimensions.
This is a short post because it immediately builds off the previous post. For positioning the points uniformly, I will use Method 2 from that post, which uses normal random variables, as it immediately gives a fast method in \(n\) dimensions.
I wrote this post and the code more for curiosity than any immediate application. But simulating a Poisson point process in this setting requires placing points uniformly on a sphere. And there are applications in that, such as Monte Carlo integration methods, as mentioned in this post, which nicely details different sampling methods.
Steps
As is the case for other shapes, simulating a Poisson point process requires two steps.
Number of points
The number of points of a Poisson point process on the surface of a sphere of radius \(r>0\) is a Poisson random variable. The mean of this random variable is \(\lambda S_{n-1}\), where \(S_{n-1}\) is the surface area of the sphere. For a ball embedded in \(n\) dimension, the area of the corresponding sphere is given by
where \(\Gamma\) is the gamma function, which is a natural generalization of the factorial. In MATLAB, we can simply use the function gamma. In Python, we need to use the SciPy function scipy.special. gamma.
Locations of points
For each point on the sphere, we generate \(n\) standard normal or Gaussian random variables, say, \(W_1, \dots, W_n\), which are independent of each other. These random variables are the Cartesian components of the random point. We rescale the components by the Euclidean norm, then multiply by the radius \(r\).
For \(i=1,\dots, n\), we obtain
$$X_i=\frac{rW_i}{(W_1^2+\cdots+W_n^2)^{1/2}}.$$
These are the Cartesian coordinates of a point uniformly scattered on a sphere with radius \(r\) and a centre at the origin.
How does it work?
In the post on the circle setting, I gave a more detailed outline of the proof, where I said the method is like the Box-Muller transform in reverse. The joint density of the normal random variables is from a multivariate normal distribution with zero correlation. This joint density a function of the Cartesian equation for a sphere. This means the density is constant on the sphere, implying that the angle of the point \((W_1,\dots, W_n)\) will be uniformly distributed.
The vector formed from the normal variables \((W_1,\dots,W_n)\) is a random variable with a chi distribution. But the final vector, which stretches from the origin to the point \((X_1,\dots,X_n)\), has length one, because we rescaled it with the Euclidean norm.
Code
The code for all my posts is located online here. For this post, the code in MATLAB and Python is here.
Further reading
I recommend this blog post, which discusses different methods for randomly placing points on spheres and inside spheres (or, rather, balls) in a uniform manner. (Embedded in two dimensions, a sphere is a circle and a ball is a disk.)
Our Method 2 for positioning points uniformly, which uses normal variables, comes from the paper:
1959, Muller, A note on a method for generating points uniformly on n-dimensional spheres.
Two recent works on this approach are the papers:
2010, Harman and Lacko, On decompositional algorithms for uniform sampling from -spheres and -balls;
2017, Voelker, Gosman, Stewart, Efficiently sampling vectors and coordinates.
In this post I’ll describe how to simulate or sample a homogeneous Poisson point process on the surface of a sphere. I have already simulated this point process on a rectangle, triangledisk, and circle.
Of course, by sphere, I mean the everyday object that is the surface of a three-dimensional ball, where this two-dimensional object is often denoted by \(S^2\). Mathematically, this is a generalization from a Poisson point process on a circle, which is slightly simpler than randomly positioning points on a disk. I recommend reading those two posts first, as a lot of the material presented here builds off them.
I have not needed such a simulation in my own work, but I imagine there are many reasons why you would want to simulate a Poisson point process on a sphere. As some motivation, we can imagine these points on a sphere representing, say, meteorites or lightning hitting the Earth.
The generating the number of points is not difficult. The trick is positioning the points on the sphere in a uniform way. As is often the case, there are various ways to do this, and I recommend this post, which lists the main ones. I will use two methods that I consider the most natural and intuitive ones, namely using spherical coordinates and normal random variables, which is what I did in the post on the circle.
Incidentally, a simple modification allows you to scatter the points uniformly inside the sphere, but you would typically say ball in mathematics, giving a Poisson point process inside a ball; see below for details.
Steps
As always, simulating a Poisson point process requires two steps.
Number of points
The number of points of a Poisson point process on the surface of a sphere of radius \(r>0\) is a Poisson random variable with mean \(\lambda S_2\), where \(S_2=4\pi r^2\) is the surface area of the sphere. (In this post I give some details for simulating or sampling Poisson random variables or, more accurately, variates.)
Locations of points
For any homogeneous Poisson point process, we need to position the points uniformly on the underlying space, which is in this case is the sphere. I now outline two different methods for doing this.
Method 1: Spherical coordinates
The first method is based on spherical coordinates \((\rho, \theta,\phi)\), where the radial coordinate \(\rho\geq 0\), and the angular coordinates \(0 \leq \theta\leq 2\pi\) and \(0\leq \phi \leq \pi\). The change of coordinates gives \(x=\rho\sin(\theta)\cos(\phi)\), \(y=\rho\sin(\theta)\sin(\phi)\), and \(z=\rho\cos(\phi)\).
Now we use Proposition 1.1 in this paper by Pitman and Ross. For each point, we generate two uniform variables \(V\) and \(\Theta\) on the respective intervals \((-1,1)\) and \((0,2\pi)\). Then we place the point with the Cartesian coordinates
$$X = r \sqrt{1-V^2} \cos\Theta, $$
$$Y = r \sqrt{1-V^2}\sin\Theta, $$
$$ Z=r V. $$
This method places a uniform point on a sphere with a radius \(r\).
How does it work?
I’ll skip the precise details, but give some interpretation of this method. The random variable \(\Phi := \arccos V\) is the \(\phi\)-coordinate of the uniform point, which implies \(\sin \Phi=\sqrt{1-V^2}\), due to basic trigonometric identities. The area element in polar coordinates is \(dA = \rho^2 \sin\phi d\phi d\theta \), which is constant with respect to \(\theta\). After integrating with respect to \(\phi\), we see that the random variable \(V=\cos\Phi\) needs to be uniform (instead of \(\Phi\)) to ensure the point is uniformly located on the surface.
Method 2: Normal random variables
For each point, we generate three standard normal or Gaussian random variables, say, \(W_x\), \(W_y\), and \(W_z\), which are independent of each other. (The term standard here means the normal random variables have mean \(\mu =0\) and standard deviation \(\sigma=1\).) The three random variables are the Cartesian components of the random point. We rescale the components by the Euclidean norm, then multiply by the radius \(r\), giving
$$X=\frac{rW_x}{(W_x^2+W_y^2+W_z^2)^{1/2}},$$
$$Y=\frac{rW_y}{(W_x^2+W_y^2+W_z^2)^{1/2}},$$
$$Z=\frac{rW_z}{(W_x^2+W_y^2+W_z^2)^{1/2}}.$$
These are the Cartesian coordinates of a point uniformly scattered on a sphere with radius \(r\) and a centre at the origin.
How does it work?
The procedure is somewhat like the Box-Muller transform in reverse. In the post on the circle setting, I gave an outline of the proof, which I recommend reading. The joint density of the normal random variables is from a multivariate normal distribution with zero correlation. This joint density is constant on the sphere, implying that the angle of the point \((W_x, W_y, W_z)\) will be uniformly distributed.
The vector formed from the normal variables \((W_x, W_y,W_z)\) is a random variable with a chi distribution. We can see that the vector from the origin to the point \((X,Y,Z)\) has length one, because we rescaled it with the Euclidean norm.
Plotting
Depending on your plotting software, the points may more resemble points on an ellipsoid than a sphere due to the different scaling of the x, y and z axes. To fix this in MATLAB, run the command: axis square. In Python, it’s not straightforward to do this, as it seems to lack an automatic function, so I have skipped it.
Results
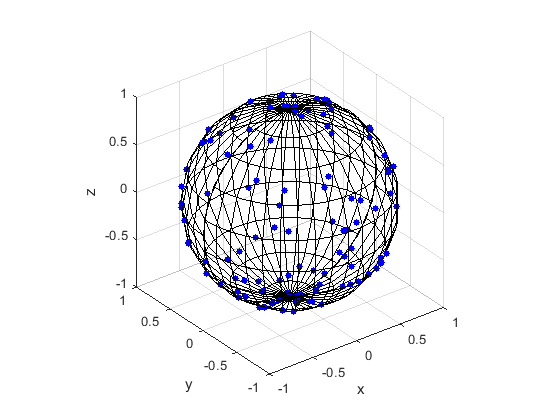
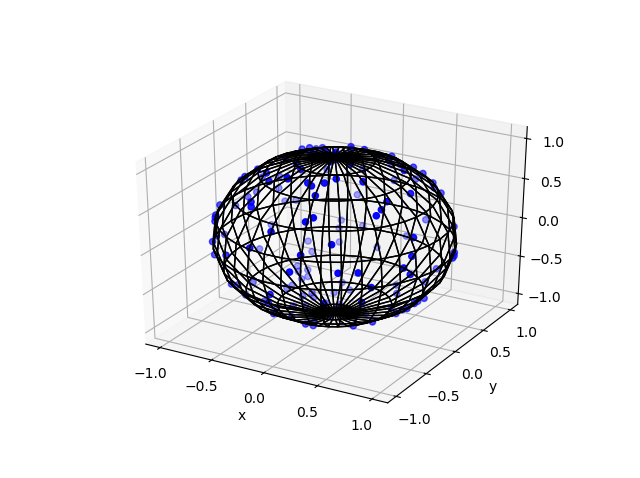
Here are some results produced by code written in MATLAB and Python. The blue points are the Poisson points on the sphere. I have used a surface plot (with clear faces) to illustrate the underling sphere in black.
MATLAB
Python
Note: The aspect ratio in 3-D Python plots tends to squash the sphere slightly, but it is a sphere.
Code
The code for all my posts is located online here. For this post, the code in MATLAB and Python is here. In Python I used the library mpl_toolkits for doing 3-D plots.
Poisson point process inside the sphere
Perhaps you want to simulate a Poisson point process inside the ball. There are different ways we can do this, but I will describe just one way, which builds off Method 1 for positioning the points uniformly. (In a later post, I will modify Method 2, giving a way to uniformly position points inside the ball.)
For this simulation method, you need to make two simple modifications to the simulation procedure.
Number of points
The number of points of a Poisson point process inside a sphere of radius \(r>0\) is a Poisson random variable with mean \(\lambda V_3\), where \(V_3=4\pi r^3\) is the volume of the sphere.
Locations of points
We will modify Method 1 as outlined above. To sample the points uniformly in the sphere, you need to generate uniform variables on the unit interval \((0,1)\), take their cubic roots, and then, multiply them by the radius \(r\). (This is akin to the step of taking the square root in the disk setting.) The random variables for the angular coordinates are generated as before.
Further reading
I recommend this blog post, which discusses different methods for randomly placing points on spheres and inside spheres (or, rather, balls) in a uniform manner. (Embedded in two dimensions, a sphere is a circle and a ball is a disk.)
Our Method 2 for positioning points uniformly, which uses normal variables, comes from the paper:
1959, Muller, A note on a method for generating points uniformly on n-dimensional spheres.
This sampling method relies upon old observations that normal variables are connected to spheres and circles. I also found this post on a similar topic. Perhaps not surprisingly, the above paper is written by the same Muller behind the Box-Muller method for sampling normal random variables.
Update: The connection between the normal distribution and rotational symmetry has been the subject of some recent 3Blue1Brown videos on YouTube.
Here is some sample Python code for creating a 3-D scatter plot.
In this post, I’ll take a break from the more theoretical posts. Instead I’ll describe how to simulate or sample a homogeneous Poisson point process on a circle. I have already simulated this point process on a rectangle, triangle and disk. In some sense, I should have done this simulation method before the disk one, as it’s easier to simulate. I recommend reading that post first, as the material presented here builds off it.
Sampling a homogeneous Poisson point process on a circle is rather straightforward. It just requires using a fixed radius and uniformly choose angles from interval \((0, 2\pi)\). But the circle setting gives an opportunity to employ a different method for positioning points uniformly on circles and, more generally, spheres. This approach uses Gaussian random variables, and it becomes much more efficient when the points are placed on high dimensional spheres.
Steps
Simulating a Poisson point process requires two steps: simulating the random number of points and then randomly positioning each point.
Number of points
The number of points of a Poisson point process on circle of radius \(r>0\) is a Poisson random variable with mean \(\lambda C\), where \(C=2\pi r\) is the circumference of the circle. You just need to be able to need to produce (pseudo-)random numbers according to a Poisson distribution.
To generate Poisson variables in MATLAB, use the poissrnd function with the argument \(\lambda C\). In Python, use either the scipy.stats.poisson or numpy.random.poisson function from the SciPy or NumPy libraries. (If you’re curious how Poisson simulation works, I suggest seeing this post for details on sampling Poisson random variables or, more accurately, variates.)
Locations of points
For a homogeneous Poisson point process, we need to uniformly position points on the underlying space, which is this case is a circle. We will look at two different ways to position points uniformly on a circle. The first is arguably the most natural approach.
Method 1: Polar coordinates
We use polar coordinates due to the nature of the problem. To position all the points uniformly on a circle, we simple generate uniform numbers on the unit interval \((0,1)\). We then multiply these random numbers by \(2\pi\).
We have generated polar coordinates for points uniformly located on the circle. To plot the points, we have to convert the coordinates back to Cartesian form by using the change of coordinates: \(x=\rho\cos(\theta)\) and \(y=\rho\sin(\theta)\).
Method 2: Normal random variables
For each point, we generate two standard normal or Gaussian random variables, say, \(W_x\) and \(W_y\), which are independent of each other. (The term standard here means the normal random variables have mean \(\mu =0\) and standard deviation \(\sigma=1\).) These two random variables are the Cartesian components of a random point. We then rescale the two values by the Euclidean norm, giving
$$X=\frac{W_x}{(W_x^2+W_y^2)^{1/2}},$$
$$Y=\frac{W_y}{(W_x^2+W_y^2)^{1/2}}.$$
These are the Cartesian coordinates of points uniformly scattered around a unit circle with centre at the origin. We multiply the two random values \(X\) and \(Y\) by the \(r>0\) for a circle with radius \(r\).
How does it work?
The procedure is somewhat like the Box-Muller transform in reverse. I’ll give an outline of the proof. The joint density of the random variables \(W_x\) and \(W_y\) is that of the bivariate normal distribution with zero correlation, meaning it has the joint density
$$ f(x,y)=\frac{1}{2\pi}e^{[-(x^2+y^2)/2]}.$$
We see that the function \(f\) is a constant when we trace around any line for which \((x^2+y^2)\) is a constant, which is simply the Cartesian equation for a circle (where the radius is the square root of the aforementioned constant). This means that the angle of the point \((W_x, W_y)\) will be uniformly distributed.
Now we just need to look at the distance of the random point. The vector formed from the pair of normal variables \((W_x, W_y)\) is a Rayleigh random variable. We can see that the vector from the origin to the point \((X,Y)\) has length one, because we rescaled it with the Euclidean norm.
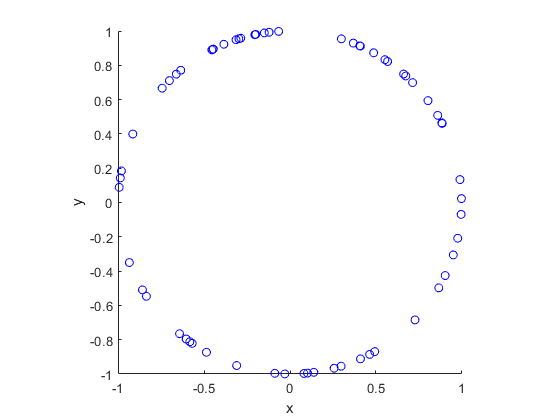
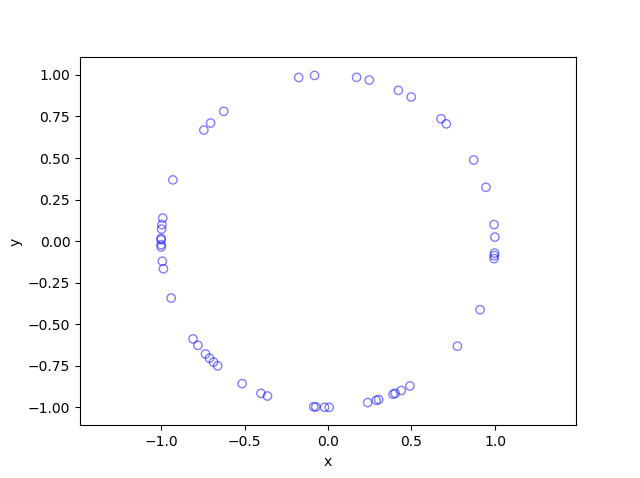
Results
I have presented some results produced by code written in MATLAB and Python. The blue points are the Poisson points on the sphere. I have used a surface plot (with clear faces) in black to illustrate the underling sphere.
MATLAB
Python
Code
The code for all my posts is located online here. For this post, the code in MATLAB and Python is here.
Further reading
I recommend this blog post, which discusses different methods for randomly placing points on spheres and inside spheres (or, rather, balls) in a uniform manner. (Embedded in two dimensions, a sphere is a circle and a ball is a disk.) A key paper on using normal variables is the following:
1959, Muller, A note on a method for generating points uniformly on n-dimensional spheres.
As I mentioned in the post on the disk, the third edition of the classic book Stochastic Geometry and its Applications by Chiu, Stoyan, Kendall and Mecke details on page 54 how to uniformly place points on a disk. It just requires a small modification for the circle.
In previous posts I have often stressed the importance of the Poisson point process as a mathematical model. But it can be unsuitable for certain mathematical models. We can generalize it by first considering a non-negative random measure, called a driving or directing measure. Then a Poisson point process, which is independent of the random driving measure, is generated by using the random measure as its intensity or mean measure. This doubly stochastic construction gives what is called a Cox point process.
In practice we don’t typically observe the driving measure. This means that it’s impossible to distinguish a Cox point process from a Poisson point process if there’s only one realization available. By conditioning on the random driving measure, we can use the properties of the Poisson point process to derive those of the resulting Cox point process.
By the way, Cox point processes are also known as doubly stochastic Poisson point processes. Guttorp and Thorarinsdottir argue that we should call them the Quenouille point processes, as Maurice Quenouille introduced an example of it before Sir David Cox. But I opt for the more common name.
In this post I’ll cover a couple examples of Cox point processes. But first I will need to give a more precise mathematical definition.
Definition
We consider a point process defined on some underlying mathematical space \(\mathbb{S}\), which is sometimes called the carrier space or state space. The underlying space is often the real line \(\mathbb{R}\), the plane \(\mathbb{R}^2\), or some other familiar mathematical space like a square lattice.
For the first definition, we use the concept of a random measure.
Let \(M\) be a non-negative random measure on \(\mathbb{S} \). Then a point process \(\Phi\) defined on some underlying space \(\mathbb{S}\) is a Cox point process driven by the intensity measure \(M\) if the conditional distribution of \(\Phi\) is a Poisson point process with intensity function \(M\).
We can give a slightly less general definition of a Cox point process by using a random intensity function.
Let \(Z=\{Z(x):x\in\mathbb{S} \}\) be a non-negative random field such that with probability one, \(x\rightarrow Z(x)\) is a locally integrable function. Then a point process \(\Phi\) defined on some underlying space \(\mathbb{S}\) is a Cox point process driven by \(Z\) if the conditional distribution of \(\Phi\) is a Poisson point process with intensity function \(Z\).
The random driving measure \(M\) is then simply the integral
$$
M(B)=\int_B Z(x)\, dx , \quad B\subseteq S.
$$
Over-dispersion
The random driving measures take different forms, giving different Cox point processes. But there is a general observation that can be made for all Cox point processes. For any region \(B \subseteq S\), it can be shown that the number of points \(\Phi (B)\) adheres to the inequality
$$
\mathbb{Var} [\Phi (B)] \geq \mathbb{E} [\Phi (B)],
$$
where \(\mathbb{Var} [\Phi (B)] \) is the variance of the random variable \(\Phi (B)\). As a comparison, for a Poisson point process \(\Phi’\), the variance of \(\Phi’ (B)\) is simply \(\mathbb{Var} [\Phi’ (B)] =\mathbb{E} [\Phi’ (B)]\). Due to its greater variance, the Cox point process is said to be over-dispersed compared to the Poisson point process.
Special cases
There is an virtually unlimited number of ways to define a random driving measure, where each one yields a different a Cox point process. But in general we are restricted by examining only tractable and interesting Cox point processes. I will give some common examples, but I stress that the Cox point process family is very large.
Mixed Poisson point process
For the random driving measure \(M\), an obvious example is the product form \(M= Y \mu \), where \(Y\) is some independent non-negative random variable and \(\mu\) is the Lebesgue measure on \(\mathbb{S}\). This driving measure gives the mixed Poisson point process. The random variable \(Y\) is the only source of randomness.
Log-Gaussian Cox point process
Instead of a random variable, we can use a non-negative random field to define a random driving measure. We then have the product \(M= Y \mu \), where \(Y\) is now some independent non-negative random field. (A random field is a collection of random variables indexed by some set, which in this case is the underlying space \(\mathbb{S}\).)
Arguably the most tractable and used random field is the Gaussian random field. This random field, like Gaussian or normal random variables, takes both negative and positive values. But if we define the random field such that its logarithm is a Gaussian field \(Z\), then we obtain the non-negative random driving measure \(M=\mu e^Z \), giving the log-Gaussian Cox point process.
This point process has found applications in spatial statistics.
Cox-Poisson line-point process
To construct this Cox point process, we first consider a Poisson line process, which I discussed previously. Given a Poisson line process, we then place an independent one-dimensional Poisson point process on each line. We then obtain an example of a Cox point process, which we could call a Cox line-point process or a Cox-Poisson line-point process. (But I am not sure of the best name.)
Researchers have recently used this point process to study wireless communication networks in cities, where the streets correspond to Poisson lines. For example, see these two preprints:
We construct the next Cox point process by first considering a Poisson point process on the space \(\mathbb{S}\) to create a shot noise term. (Shot noise is just the sum of some function over all the points of a point process.) We then use it as the driving measure of the Cox point process.
More specifically, we first introduce a kernel function \(k(\cdot,\cdot)\) on \(\mathbb{S}\), where \(k(x,\cdot)\) is a probability density function for all points \(x\in \mathbb{S}\). We then consider a Poisson point process \(\Phi’\) on \(\mathbb{S}\times (0,\infty)\). We assume the Poisson point process \(\Phi’\) has a locally integrable intensity function \(\mu \).
(We can interpret the point process \(\Phi’\) as a spatially-dependent marked Poisson point process, where the unmarked Poisson point process is defined on \(\mathbb{S}\). We then assume each point \(X\) of this unmarked point process has a mark \(T \in (0,\infty)\) with probability density \(\mu(X,t)\).)
The resulting shot noise
$$
Z(x)= \sum_{(Y,T)\in \Phi’} T \, k(Y,x)\,,
$$
gives the random field. We then use it as the random intensity function to drive the shot-noise Cox point process.
In previous posts, I have detailed how to simulate non-Poisson point processes such as the Matérn and Thomas cluster point processes. These are examples of a Neyman-Scott point process, which is a special case of a shot noise Cox point process. All these point processes find applications in spatial statistics.
Simulation
Unfortunately, there is no universal way to simulate all Cox point processes. (And even if there were one, it would not be the most optimal way for every Cox point process.) The simulation method depends on how the Cox point process is constructed, which usually means how its directing or driving measure is defined.
In previous posts I have presented ways (with code) to simulate these Cox point processes:
In addition to the Matérn and Thomas point processes, there are ways to simulate more general shot noise Cox point processes. I will cover that in another post.
In two previous posts, here and here, I discussed the importance of the quantity called the signal-to-interference ratio, which is usually abbreviated as SIR, for studying communication in wireless networks. In everyday terms, for a listener to hear a certain speaker in a room full of people speaking, the ratio of the speaker’s volume to the sum of the volumes of everyone else heard by the listener. The SIR is the communication bottleneck for any receiver and transmitter pair in a wireless network.
But the strengths (or power values) of the signals are of course also important. In this post I will detail how we can model them using a a simple network model with a single observer.
Propagation model
For a transmitter located at \(X_i\in \mathbb{R}^2\), researchers usually attempt to represent the received power of the signal \(P_i\) with a propagation model. Assuming the power is received at \(x\in \mathbb{R}^2\), this mathematical model consists of a random and a deterministic component taking the general form
$$
P_i(x)=F_i\,\ell(|X_i-x|) ,
$$
where \(\ell(r)\) is a non-negative function in \(r>0\) and \(F_i\) is a non-negative random variable.
The function \(\ell(r)\) is called the pathloss function, and common choices include \(\ell(r)=(\kappa r)^{-\beta}\) and \(\ell(r)=\kappa e^{-\beta r}\), where \(\beta>0\) and \(\kappa>0\) are model constants.
The random variables \(F_i\) represent signal phenomena such as multi-path fading and shadowing (also called shadow fading), caused by the signal interacting with the physical environment such as buildings. It is often called fading or shadowing variables.
We assume the transmitters locations \(X_1,\dots,X_n\) are on the plane \(\mathbb{R}^2\). Researchers typically assume they form a random point process or, more precisely, the realization of a random point process.
From two dimensions to one dimension
For studying wireless networks, a popular technique is to consider a wireless network from the perspective of a single observer or user. Researchers then consider the incoming or received signals from the entire network at the location of this observer or user. They do this by considering the inverses of the signal strengths, namely
Mathematically, this random function is simply a mapping from the two-dimensional plane \(\mathbb{R}^2\) to the one-dimensional non-negative real line \(\mathbb{R}_0^+=[0,\infty)\).
If the transmitters are located according to a non-random point pattern or a random point process, this random mapping generates a random point process on the non-negative real line. The resulting one-dimensional point process of the values \(L_1,L_2,\dots, \) has been called (independently) propagation (loss) process or path loss (with fading) process. More recently, my co-authors and I decided to call it a projection process, but of course the precise name doesn’t mattter
Intensity measure of signal strengths
Assuming a continuous monotonic path loss function \(\ell\) and the fading variables \(F_1, F_2\dots\) are iid, if the transmitters form a stationary random point process with intensity \(\lambda\), then the inverse signal strengths \(L_1,L_2,\dots \) form a random point process on the non-negative real line with the intensity measure \(M\).
where \(\ell^{-1}\) is the generalized inverse of the function \(\ell\). This expression can be generalized for a non-stationary point process with general intensity measure \(\Lambda\).
The inverses \(1/L_1,1/L_2,\dots \), which are the signal strengths, forprocess with intensity measure
Poisson transmitters gives Poisson signal strengths
Assuming a continuous monotonic path loss function \(\ell\) and the fading variables \(F_1, F_2\dots\) are iid, if the transmitters form a Poisson point process with intensity \(\lambda\), then the inverse signal strengths \(L_1,L_2,\dots \) form a Poisson point process on the non-negative real line with the intensity measure \(M\).
If \(L_1,L_2,\dots \) form a homogeneous Poisson point process, then the inverses \(1/L_1,1/L_2,\dots \) will also form a Poisson point process with intensity measure \(\bar{M}(s) =\lambda \pi \mathbb{E}( [\ell( F/s)^{-1} ]^2). \)
Propagation invariance
For \(\ell(r)=(\kappa r)^{-\beta}\) , the expression for the intensity measure \(M\) reduces to
$$
M(t) = \lambda \pi t^{-2/\beta} \mathbb{E}( F^{-2/\beta})/\kappa^2.
$$
What’s striking here is that information of the fading variable \(F\) is captured simply by one moment \(\mathbb{E}( F^{-2/\beta}) \). This means that two different distributions will give the same results as long as this moment is matching. My co-authors and I have been called this observation propagation invariance.
Some history
To study just the (inverse) signal strengths as a point process on the non-negative real line was a very useful insight. It was made independently in these two papers:
2008, Haenggi, A geometric interpretation of fading in wireless networks: Theory and applications;
2010, Błaszczyszyn, Karray, and Klepper, Impact of the geometry, path-loss exponent and random shadowing on the mean interference factor in wireless cellular networks.
My co-authors and I presented a general expression for the intensity measure \(M\) in the paper:
2018, Keeler, Ross and Xia, When do wireless network signals appear Poisson?.
This paper is also contains examples of various network models.
With Bartek Błaszczyszyn, Sayan Mukherjee, and Martin Haenggi, I co-wrote a short monograph on SINR models called Stochastic Geometry Analysis of Cellular Networks, which is written at a slightly more advanced level. The book puts an emphasis on studying the point process formed from inverse signal strengths, we call the projection process.
In the previous post I discussed the signal-to-interference-plus ratio or SIR in wireless networks. If noise is included, then then signal-to-interference-plus-noise ratio or just SINR. But I will just write about SIR, as most results that hold for SIR, will also hold for SINR without any great mathematical difficulty.
The SIR is an important quantity due to reasons coming from information theory. If you’re unfamiliar with it, I suggest reading the previous post.
In this post, I will describe a very popular mathematical model of the SIR, which I like to call the standard model. (This is not a term used in the literature as I have borrowed it from physics.)
Definition of SIR
To define the SIR, we consider a wireless network of \(n\) transmitters with positions located at \(X_1,\dots,X_n\) in some region of space. At some location \(x\), we write \(P_i(x)\) to denote the power value of a signal received at \(x\) from transmitter \(X_i\). Then at location \(x\), the SIR with respect to transmitter \(X_i\) is
$$
\text{SIR}(x,X_i) := \frac{P_i(x)}{\sum\limits_{j\neq i} P_j(x)} .
$$
Researchers usually attempt to represent the received power of the signal \(P_i(x)\) with a propagation model. This mathematical model consists of a random and a deterministic component given by
$$
P_i(x)=F_i\ell(|X_i-x|) ,
$$
where \(\ell(r)\) is a non-negative function in \(r\geq 0\) and \(F_i\) is a non-negative random variable. The function \(\ell(r)\) is often called the path loss function. The random variables represent random fading or shadowing.
Standard model
Based on the three model components of fading, path loss, and transmitter locations, there are many combinations possible. That said, researchers generally (I would guess, say, 90 percent or more) use a single combination, which I call the standard model.
The three standard model assumptions are:
Singular power law path loss \(\ell(r)=(\kappa r)^{-\beta}\).
Why these three? Well, in short, because they work very well together. Incredibly, it’s sometimes possible to get relatively a simple mathematical expression for, say, the coverage probability \(\mathbb{P}[\text{SIR}(x,X_i)>\tau ]\), where \(\tau>0\).
I’ll now detail the reasons more specifically.
Path loss
The \(\ell(r)=(\kappa r)^{-\beta}\) is very simple, despite having a singularity at \(r=0\). This allows simple algebraic manipulation of equations.
Some, such as myself, are initially skeptical of this function as it gives an infinitely strong signal at the transmitter due to the singularity in the function \(\ell(r)=(\kappa r)^{-\beta}\). More specifically, the path loss of the signal from transmitter \(X_i\) approaches infinity as \(x\) approaches \(X_i\) .
But apparently, overall, the singularity does not have a significant impact on most mathematical results, at least qualitatively. That said, one still observe consequences of this somewhat physically unrealistic model assumption. And I strongly doubt enough care is taken by researchers to observe and note this.
Fading and shadowing variables
Interestingly, the original reason why exponential variables were used is because it allowed the SIR problem to be reformulated into a problem of a Laplace transform of a random variable, which for a random variable \(Y\) is defined as
The reason for this connection is that the tail distribution of an exponential variable \(F\) with mean \(\mu\) is simply \(\mathbb{P}(F>t)= e^{-t/\mu}\). In short, with the exponential assumption, various conditioning arguments eventually lead to Laplace transforms of random variables.
Transmitters locations
No prizes for guessing that researcher overwhelmingly use a (homogeneous) Poisson point process for the transmitter (or receiver) locations. When developing mathematical models with point processes, if you can’t get any results with the Poisson point process, then abandon all hope.
It’s the easier to work with this point process due to its independence property, which leads to another useful property. For Poisson point process, the Palm distribution is known, which is the distribution of a point process conditioned on a point (or collection of points) existing in a specific location of the underlying space on which the point process is defined. In general, the Palm distribution is not known for many point processes.
Random propagation effects can lead to Poisson
A lesser known reason why researchers would use the Poisson point process is that, from the perspective of a single observer in the network, it can be used to capture the randomness in the signal strengths. Poisson approximation results in probability imply that randomly perturbing the signal strengths can make signals appear more Poisson, by which I mean the signal strengths behave stochastically or statistically as though they were created by a Poisson network of transmitters.
The end result is that a non-Poisson network can appear more Poisson, even if the transmitters do not resemble (the realization of) a Poisson point process. The source of randomness that makes a non-Poisson network appear more Poisson is the random propagation effects of fading, shadowing, randomly varying antenna gains, and so on, or some combination of these.
2009, Haenggi, Andrews, Baccelli, Dousse, Franceschetti, Stochastic Geometry and Random Graphs for the Analysis and Design of Wireless Networks.
This paper by my co-authors and I has some details on standard model and why a general network model behaving Poisson in terms of the signal strengths:
2018, Keeler, Ross and Xia, When do wireless network signals appear Poisson?.
Finally, I co-wrote with Bartek Błaszczyszyn, Sayan Mukherjee, and Martin Haenggi a short monograph on SINR models called Stochastic Geometry Analysis of Cellular Networks, which is written at a slightly more advanced level. This book has a section on why signal strengths appear Poisson.