Basic information theory says that for a signal to successfully communicate across any communication link, the signal strength must be stronger than that of the background noise, leading to the fundamental quantity known as signal-to-noise ratio. Information theory holds in very general (or, in mathematical speak, abstract) settings. The communication could be, for example, a phone call on an old wired landline, two people talking in a bar, or a hand-written letter, for which the respective signals in these examples are the electrical current, speaker’s voice, and the writing. (Respective examples of noise could be, for example, thermal noise in the wires, loud music, or coffee stains on the letter.)
In wireless networks, it’s possible for a receiver to simultaneously detect signals from multiple transmitters, but the receiver typically only wants to receive one signal. The other unwanted or interfering signals form a type of noise, which is usually called interference, and the other (interfering) transmitters are called interferers. Consequently, researchers working on wireless networks study the signal-to-interference ratio, which is usually abbreviated as SIR. Another name for the SIR is carrier-to-interference ratio.
If we also include background noise, which is coming not from the interferers, then the quantity becomes the signal-to-interference-plus-noise ratio or just SINR. But I will just write about SIR, though jumping from SIR to SINR is usually not difficult mathematically.
The concept of SIR makes successful communication more difficult to model and predict, as it just doesn’t depend on the distance of the communication link. Putting the concept in everyday terms, for a listener to hear a certain speaker in a room full of people all speaking to the listener, it is not simply the distance to the speaker, but rather the ratio of the speaker’s volume to the sum of the volumes of everyone else heard by the listener. The SIR is the communication bottleneck for any receiver and transmitter pair in a wireless network.
In wireless network research, much work has been done to examine and understand communication success in terms of interference and SIR, which has led to a popular mathematical model that incorporates how signals propagate and the locations of transmitters and receivers.
Definition
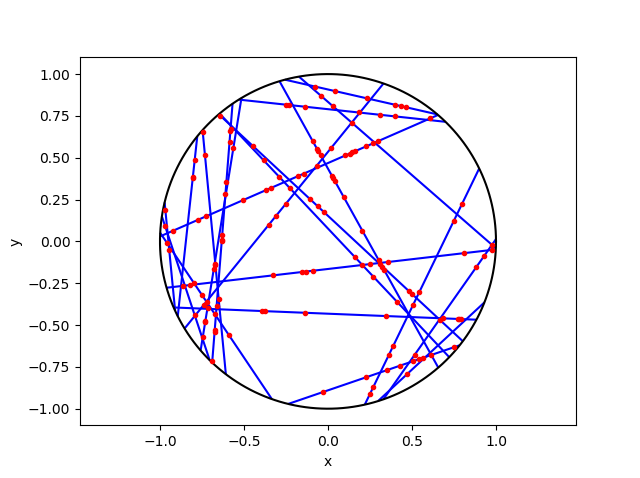
To define the SIR, we consider a wireless network of transmitters with positions located at \(X_1,\dots,X_n\) in some region of space. At some location \(x\), we write \(P_i(x)\) to denote the power value of a signal received at \(x\) from transmitter \(X_i\). Then at location \(x\), the SIR with respect to transmitter \(X_i\) is
$$
\text{SIR}(x,X_i) :=\frac{P_i(x)}{\sum\limits_{j\neq i} P_j(x)} =\frac{P_i(x)}{\sum\limits_{j=1}^{n} P_j(x)-P_i(x)} .
$$
The numerator is the signal and the denominator is the interference. This ratio tells us that increasing the number of transmitters \(n\) decreases the original SIR values. But then, in exchange, there is a greater number of transmitters for the receiver to connect to, some of which may have larger \(P_i(x)\) values and, subsequently, SIR values. This delicate trade-off makes it challenging and interesting to mathematically analyze and design networks that deliver high SIR values.
Researchers usually assume that the SIR is random. A quantity of interest is the tail distribution of the SIR, namely
$$
\mathbb{P}[\text{SIR}(x,X_i)>\tau ] := \frac{P_i(x)}{\sum\limits_{j\neq i} P_j(x)} \,,
$$
where \(\tau>0\) is some parameter, sometimes called the SIR threshold. For a given value of \(\tau\), the probability \(\mathbb{P}[\text{SIR}(x,X_i)>\tau]\) is sometimes called the coverage probability, which is simply the probability that a signal coming from \(X_i\) can be received successfully at location \(x\).
Mathematical models
Propagation
Researchers usually attempt to represent the received power of the signal \(P_i(x)\) with a propagation model. This mathematical model consists of a random and a deterministic component taking the general form
$$
P_i(x)=F_i\ell(|X_i-x|) ,
$$
where \(F_i\) is a non-negative random variable and \(\ell(r)\) is a non-negative function in \(r \geq 0\).
Path loss
The function \(\ell(r)\) is called the path loss function, and common choices include \(\ell(r)=(\kappa r)^{-\beta}\) and \(\ell(r)=\kappa e^{-\beta r}\), where \(\beta>0\) and \(\kappa>0\) are model constants, which need to be fitted to (or estimated with) real world data.
Researchers generally assume that the so-called path loss function \(\ell(r)\) is decreasing in \(r\), but actual path loss (that is, the change in signal strength over a path travelled) typically increases with distance \(r\). Researchers originally assumed path loss functions to be increasing, not decreasing, giving the alternative (but equivalent) propagation model
$$
P_i(x)= F_i/\ell(|X_i-x|).
$$
But nowadays researchers assume that the function \(\ell(r)\) is decreasing in \(r\). (Although, based on personal experience, there is still some disagreement on the convention.)
Fading and shadowing
With the random variable \(F_i\), researchers seek to represent signal phenomena such as multi-path fading and shadowing (also called shadow fading), caused by the signal interacting with the physical environment such as buildings. These variables are often called fading or shadowing variables, depending on what physical phenomena they are representing.
Typical distributions for fading variables include the exponential and gamma distributions, while the log-normal distribution is usually used for shadowing. The entire collection of fading or shadowing variables is nearly always assumed to be independent and identically distributed (iid), but very occasionally random fields are used to include a degree of statistical dependence between variables.
Transmitters locations
In general, we assume the transmitters locations \(X_1,\dots,X_n\) are on the plane \(\mathbb{R}^2\). To model interference, researchers initially proposed non-random models, but they were considered inaccurate and intractable. Now researchers typically use random point processes or, more precisely, the realizations of random point processes for the transmitter locations.
Not surprisingly, the first natural choice is the Poisson point process. Other point processes have been used such as Matérn and Thomas cluster point processes, and Matérn hard-core point processes, as well as determinantal point processes, which I’ll discuss in another post.
Some history
Early random models of wireless networks go back to the 60s and 70s, but these were based simply on geometry: meaning a transmitter could communicate successfully to a receiver if they were closer than some fixed distance. Edgar Gilbert created the field of continuum percolation with this significant paper:
- 1961, Gilbert, Random plane networks.
Interest in random geometrical models of wireless networks continued into the 70s and 80s. But there was no SIR in these models.
Motivated by understanding SIR, researchers in the late 1990s and early 2000s started tackling SIR problems by using a random model based on techniques from stochastic geometry and point processes. Early papers include:
- 1997, Baccelli, Klein, Lebourges ,and Zuyev, Stochastic geometry and architecture of communication networks;
- 2003, Baccelli and Błaszczyszyn , On a coverage process ranging from the Boolean model to the Poisson Voronoi tessellation, with applications to wireless communications;
- 2006, Baccelli, Mühlethaler, and Błaszczyszyn, An Aloha protocol for multihop mobile wireless networks.
But they didn’t know that some of their results had already been discovered independently by researchers working on wireless networks in the early 1990s. These papers include:
- 1994, Pupolin and Zorzi, Outage probability in multiple access packet radio networks in the presence of fading;
- 1990, Sousa and Silvester, Optimum transmission ranges in a direct-sequence spread-spectrum multihop packet radio network.
The early work focused more on small-scale networks like wireless ad hoc networks. Then the focus shifted dramatically to mobile or cellular phone networks with the publication of the paper:
- 2011, Andrews, Baccelli, Ganti, A tractable approach to coverage and rate in cellular networks.
It’s can be said with confidence that this paper inspired much of the interest in using point processes to develop models of wireless networks. The work generally considers the SINR in the downlink channel for which the incoming signals originate from the phone base stations.
Further reading
A good starting point on this topic is the Wikipedia article Stochastic geometry models of wireless networks.
Another good resource is the paper:
- 2009, Haenggi, Andrews, Baccelli, Dousse, Franceschetti, Stochastic Geometry and Random Graphs for the Analysis and Design of Wireless Networks.
Early books on the subject include the two-volume textbooks Stochastic Geometry and Wireless Networks by François Baccelli and Bartek Błaszczyszyn, where the first volume is on theory and the second volume is on applications. Martin Haenggi wrote a very readable introductory book called Stochastic Geometry for Wireless networks.
Finally, Bartek Błaszczyszyn, Sayan Mukherjee, Martin Haenggi, and I wrote a short book on SINR models called Stochastic Geometry Analysis of Cellular Networks, which is written at a slightly more advanced level. The book puts an emphasis on studying the point process formed from inverse signal strengths, which we call the projection process.