One of the most important stochastic processes is Poisson stochastic process, often called simply the Poisson process. In a previous post I gave the definition of a stochastic process (also called a random process) alongside some examples of this important random object, including counting processes. The Poisson (stochastic) process is a counting process. This continuous-time stochastic process is a highly studied and used object. It plays a key role in different probability fields, particularly those focused on stochastic processes such as stochastic calculus (with jumps) and the theories of Markov processes, queueing, point processes (on the real line), and Levy processes.
The points in time when a Poisson stochastic process increases form a Poisson point process on the real line. In this setting the stochastic process and the point process can be considered two interpretations of the same random object. The Poisson point process is often just called the Poisson process, but a Poisson point process can be defined on more generals spaces. In some literature, such as the theory of Lévy processes, a Poisson point process is called a Poisson random measure, differentiating the Poisson point process from the Poisson stochastic process. Due to the connection with the Poisson distribution, the two mathematical objects are named after Simeon Poisson, but he never studied these random objects.
The other important stochastic process is the Wiener process or Brownian (motion process), which I cover in another post. The Wiener process is arguably the most important stochastic process. I have written that post and the current one with the same structure and style, reflecting and emphasizing the similarities between these two fundamental stochastic process.
In this post I will give a definition of the homogenous Poisson process. I will also describe some of its key properties and importance. In future posts I will cover the history and generalizations of this stochastic process.
Definition
In the stochastic processes literature there are different definitions of the Poisson process. These depend on the settings such as the level of mathematical rigour. I give a mathematical definition which captures the main characteristics of this stochastic process.
Definition: Homogeneous Poisson (stochastic) process
An integer-valued stochastic process \(\{N_t:t\geq 0 \}\) defined on a probability space \((\Omega,\mathcal{A},\mathbb{P})\) is a homogeneous Poisson (stochastic) process if it has the following properties:
- The initial value of the stochastic process \(\{N_t:t\geq 0 \}\) is zero with probability one, meaning \(P(N_0=0)=1\).
- The increment \(N_t-N_s\) is independent of the past, that is, \(N_u\), where \(0\leq u\leq s\).
- The increment \(N_t-N_s\) is a Poisson variable with mean \(\lambda (t-s)\).
In some literature, the initial value of the stochastic process may not be given. Alternatively, it is simply stated as \(N_0=0\) instead of the more precise (probabilistic) statement given above.
Also, some definitions of this stochastic process include an extra property or two. For example, from the above definition, we can infer that increments of the homogeneous Poisson process are stationary due to the properties of the Poisson distribution. But a definition may include something like the following property, which explicitly states that this stochastic process is stationary.
- For \(0\leq u\leq s\), the increment \(N_t-N_s\) is equal in distribution to \(N_{t-s}\).
The definitions may also describe the continuity of the realizations of the stochastic process, known as sample paths, which we will cover in the next section.
It’s interesting to compare these defining properties with the corresponding ones of the standard Wiener stochastic process. Both stochastic processes build upon divisible probability distributions. Using this property, Lévy processes generalize these two stochastic processes.
Properties
The definition of the Poisson (stochastic) process means that it has stationary and independent increments. These are arguably the most important properties as they lead to the great tractability of this stochastic process. The increments are Poisson random variables, implying they can have only positive (integer) values.
The Poisson (stochastic) process exhibits closure properties, meaning you apply certain operations, you get another Poisson (stochastic) process. For example, if we sum two independent Poisson processes \(X= \{X_t:t\geq 0 \}\) and \(Y= \{Y_t:t\geq 0 \}\), then the resulting stochastic process \(Z=Z+Y = \{N_t:t\geq 0 \}\) is also a Poisson (stochastic) process. Such properties are useful for proving mathematical results.
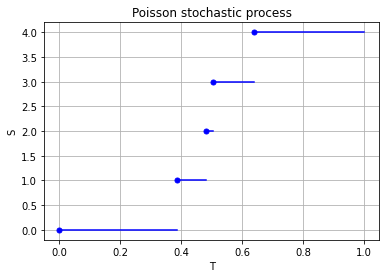
Properties such as independence and stationarity of the increments are so-called distributional properties. But the sample paths of this stochastic process are also interesting. A sample path of a Poisson stochastic process is almost surely non-decreasing, being constant except for jumps of size one. (The term almost surely comes from measure theory, but it means with probability one.) There are only finitely number of jumps in each finite time interval.
The homogeneous Poisson (stochastic) process has the Markov property, making it an example of a Markov process. The homogenous Poisson process \(N=\{ N_t\}_{t\geq 0}\)s not a martingale. But interestingly, the stochastic process is \(\{ W_t – \lambda t\}_{t\geq 0}\) is a martingale. (Such relations have been used to study such stochastic processes with tools from martingale theory.)
Stochastic or point process?
The Poisson (stochastic) process is a discrete-valued stochastic process in continuous time. The relation these types of stochastic processes and point process is a subtle one. For example, David Cox and Valerie Isham write on page 3 of their monograph:
The borderline between point processes and a number of other kinds of stochastic process is not sharply defined. In particular, any stochastic process in continuous time in which the sample paths are step functions, and therefore any any process with a discrete state space, is associated with a point process, where a point is a time of transition or, more generally, a time of entry into a pre-assigned state or set of states. Whether it is useful to look at a particular process in this way depends on the purpose of the analysis.
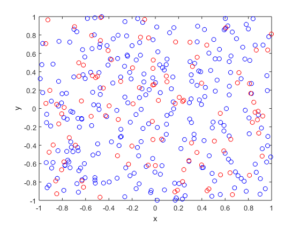
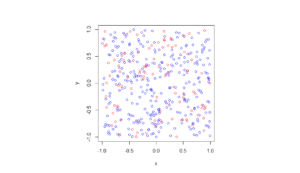
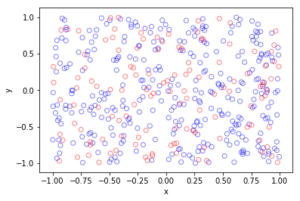
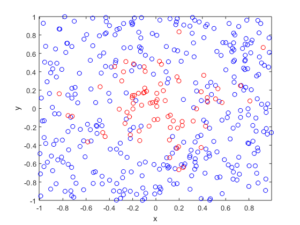
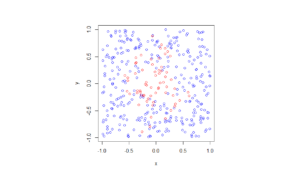
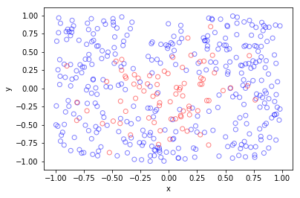
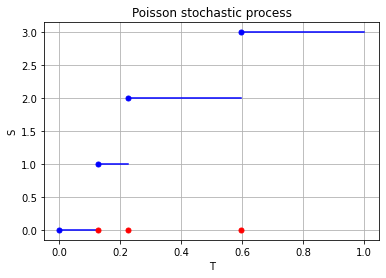
For the Poisson case, this association is presented in the diagram below. We can see the Poisson point process (in red) associated with the Poisson (stochastic) process (in blue) by simply looking at the time points where jumps occur.
Importance
Playing a prominent role in the theory of probability, the Poisson (stochastic) process is a highly important and studied stochastic process. It has connections to other stochastic processes and is central in queueing theory and random measures.
The Poisson process is a building block for more complex continuous-time Markov processes with discrete state spaces, which are used as mathematical models. It is also essential in the study of jump processes and subordinators.
The Poisson (stochastic) process is a member of some important families of stochastic processes, including Markov processes, Lévy processes, and birth-death processes. This stochastic process also has many applications. For example, it plays a central role in quantitative finance. It is also used in the physical sciences as well as some branches of social sciences, as a mathematical model for various random phenomena.
Generalizations and modifications
For the Poisson (stochastic) process, the index set and state space are respectively the non-negative numbers and counting numbers, that is \(T=[0,\infty)\) and \(S=0, 1, \dots\), so it has a continuous index set but a discrete state space. Consequently, changing the state space, index set, or both offers an ways for generalizing and modifying the Poisson (stochastic) process.
Simulation
The defining properties of the Poisson stochastic process, namely independence and stationarity of increments, results in it being easy to simulate. The Poisson stochastic process can be simulated provided random variables can be simulated or sampled according to a Poisson distributions, which I have covered in this and this post.
Simulating a Poisson stochastic process is similar to simulating a Poisson point process. (Basically, it is the same method in a one-dimensional setting.) But I will leave the details of sampling this stochastic process for another post.
Further reading
Here are some related links:
- https://www.probabilitycourse.com/chapter11/11_0_0_intro.php
- https://www.randomservices.org/random/poisson/index.html
- https://encyclopediaofmath.org/wiki/Poisson_process
A very quick history of Wiener process and the Poisson (point and stochastic) process is covered in this talk by me.
In terms of books, the Poisson process has not received as much attention as the Wiener process, which is typically just called the Brownian (motion) process. That said, any book covering queueing theory will cover the Poisson (stochastic) process.
More advanced readers can read about the Poisson (stochastic) process, the Wiener (or Brownian (motion)) process, and other Lévy processes:
- Kyprianou, Fluctuations of Lévy Processes with Applications;
- Bertoin, Lévy Processes;
- Applebaum, Lévy Processes and Stochastic Calculus.
On this topic, I recommend the introductory article:
- 2004, Applebaum, Lévy Processes – From Probability to Finance and Quantum Groups.
This stochastic process is of course also covered in general books on stochastics process such as:
- Resnick, Adventures in Stochastic Processes;
- Parzen, Stochastic Processes;
- Durrett, Essentials of Stochastic Processes;
- Rosenthal, A First Look at Stochastic Processes.