

A Matérn cluster point process is a type of cluster point process, meaning that its randomly located points tend to form random clusters. (I skip the details here, but by using techniques from spatial statistics, it is possible to make the definition of clustering more precise.) This point process is an example of a family of cluster point processes known as Neyman-Scott point processes, which have been used in spatial statistics and telecommunications.
I should point out that the Matérn cluster point process should not be confused with the Matérn hard-core point process, which is a completely different type of point process. (For a research article, I have actually written code in MATLAB that simulates this type of point process.) Bertril Matérn proposed at least four types of point processes, and his name also refers to a specific type of covariance function used to define Gaussian processes.
Overview
Simulating a Matérn cluster point process requires first simulating a homogeneous Poisson point process with an intensity \(\lambda>0\) on some simulation window, such as a rectangle, which is the simulation window I will use here. Then for each point of this underlying point process, simulate a Poisson number of points with mean \(\mu>0\) uniformly on a disk with a constant radius \(r>0\). The underlying point process is sometimes called the parent (point) process, and its points are centres of the cluster disks.
The subsequent point process on all the disks is called daughter (point) process and it forms the clusters. I have already written about simulating the homogeneous Poisson point processes on a rectangle and a disk, so those posts are good starting points, and I will not focus too much on details for these steps.
Edge effects
The main challenge behind sampling this point process, which I originally forgot about in an earlier version of this post, is that it’s possible for daughter points to appear in the simulation window that come from parents points outside the simulation window. In other words, parents points outside the simulation window contribute to points inside the window.
To remove these edge effects, the point processes must be simulated on an extended version of the simulation window. Then only the daughter points within the simulation window are kept and the rest are removed. Consequently, the points are simulated on an extended window, but we only see the points inside the simulation window.
To create the extended simulation window, we can add a strip of width \(r\) all around the simulation window. Why? Well, the distance \(r\) is the maximum distance from the simulation window that a possibly contributing parent point (outside the simulation window) can exist, while still having daughter points inside the simulation window. This means it is impossible for a hypothetical parent point beyond this distance (outside the extended window) to generate a daughter point that can fall inside the simulation window.
Steps
Number of points
Simulate the underlying or parent Poisson point process on the rectangle with \(N_P\) parent points. Then for each parent point, simulate a Poisson number of offspring or daughter points, where each parent point now has \(D_i\) number of offspring points.
Then the total number of offspring points is simply \(N=D_1+\dots +D_{P}=\sum_{i=1}^{N_P}D_i \). The random variables \(P\) and \(D_i\) are Poisson random variables with respective means \(\lambda A\) and \(\mu\), where \(A\) is the area of the rectangular simulation window. To simulate these random variables in MATLAB, use the poissrnd function. To do this in R, use the standard function rpois. In Python, we can use either functions scipy.stats.poisson or numpy.random.poisson from the SciPy or NumPy libraries.
Locations of points
The points of the parent point process are randomly positioned by using Cartesian coordinates. For a homogeneous Poisson point process, the \(x\) and \(y\) coordinates of each point are independent uniform points, which is also the case for the binomial point process, covered in a previous post. The points of all the daughter point process are randomly positioned by using polar coordinates. For a homogeneous Poisson point process, the \(\theta\) and \(\rho\) coordinates of each point are independent variables, respectively with uniform and triangle distributions, which was covered in a previous post. Then we convert coordinates back to Cartesian form, which is easily done in MATLAB with the pol2cart function. In languages without such a function: \(x=\rho\cos(\theta)\) and \(y=\rho\sin(\theta)\).
Shifting all the points in each cluster disk
In practice (that is, in the code), all the daughter points are simulated in a disk with its centre at the origin. Then for each cluster disk, all the points have to be shifted to the origin is the center of the cluster, which completes the simulation step.
To use vectorization in the code, the coordinates of each cluster point are repeated by the number of daughters in the corresponding cluster by using the functions repelem in MATLAB, rep in R, and repeat in Python.
Code
I’ll now give some code in MATLAB, R and Python, which you can see are all very similar. It’s also located here.
MATLAB
The MATLAB code is located here.
R
The R code is located here.
Of course, as I have mentioned before, simulating a spatial point processes in R is even easier with the powerful spatial statistics library spatstat. The Matérn cluster point process is simulated by using the function rMatClust, but other cluster point processes, including Neyman-Scott types, are possible.
Python
The Pyhon code is located here.
Note: in previous posts I used the SciPy functions for random number generation, but now use the NumPy ones, but there is little difference, as SciPy builds off NumPy.
Julia
After writing this post, I later wrote the code in Julia. The code is here and my thoughts about Julia are here.
Results
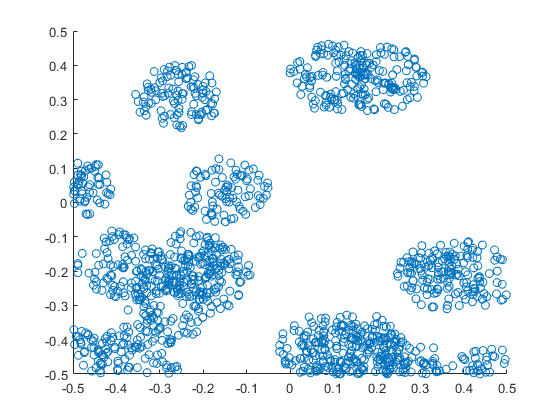
MATLAB
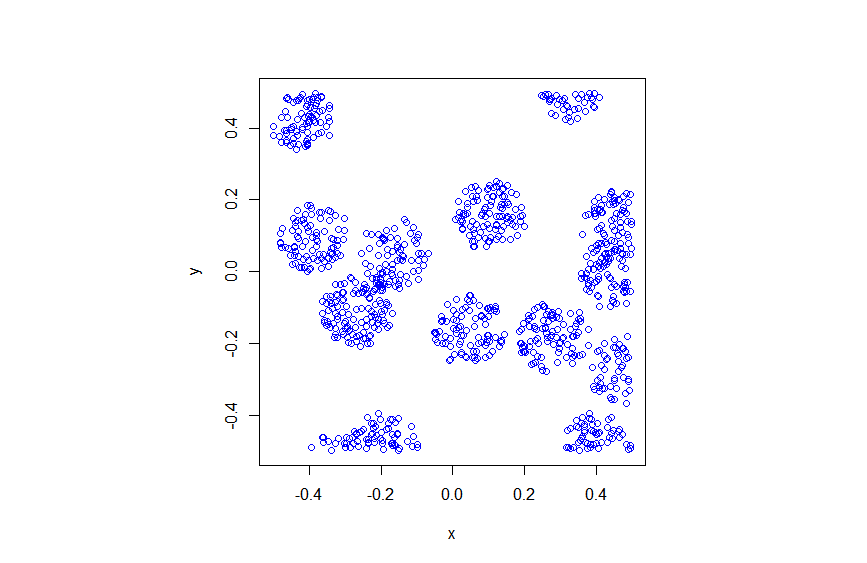
R
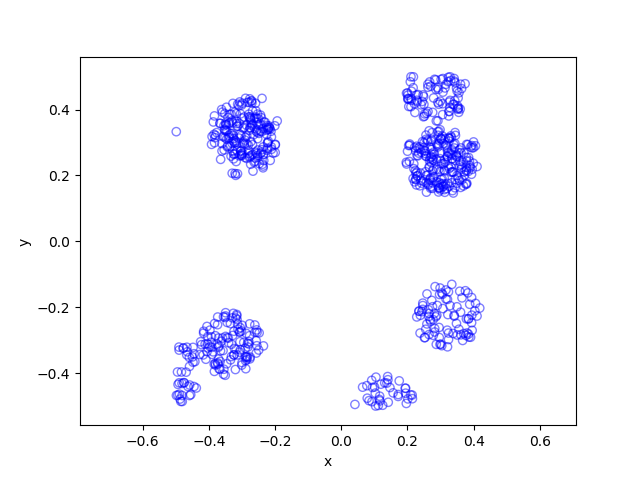
Python
Further reading
Matérn cluster point processes and more generally Neyman-Scott point processes are covered in standard books on the related fields of spatial statistics, point processes and stochastic geometry, such as the following: Spatial Point Patterns: Methodology and Applications with R by Baddeley, Rubak and Turner, on page 461; Statistical Analysis and Modelling of Spatial Point Patterns Statistics by Illian, Penttinen, Stoyan, amd Stoyan, Section 6.3.2, starting on page 370; Stochastic Geometry and its Applications by Chiu, Stoyan, Kendall and Mecke, on page 173; and; Statistical Inference and Simulation for Spatial Point Processes by Moller and Waagepetersen, in Section 5.3. I would probably recommend the first two books for beginners.
The Matérn point process has also appeared in models of wireless networks, which we covered in the book Stochastic Geometry Analysis of Cellular Networks by Błaszczyszyn, Haenggi, Keeler, and Mukherjee, Section 8.1.8.
I mentioned above the book Spatial Point Patterns: Methodology and Applications with R , which is written by spatial statistics experts Baddeley, Rubak and Turner. It covers the spatial statistics (and point process simulation) R-package spatstat.
Thank you for your great effort.
But I have a question …
How to separate clusters centers such that no overlap between the clusters can occur?
Thank you for your feedback.
Your distance requirement would form a different point process. For the Matérn cluster point process, the cluster (that is, disk) centres form a Poisson point process. For your requirement, you would need to replace the Poisson point process with a hard-core point process. For this underlying point process, no two (or more ) points are closer than some fixed distance. If the cluster diameter is r, then that distance is 2*r, implying a hard-core of radius r.
For example, you could use the Matérn hard-core point process, which is another point process proposed by Matérn. As mentioned in this post, I wrote code to simulate two different types of Matérn hard-core point processes. (There are three types of Matérn hard-core point processes, but the third type is more complicated to simulated.)
The simulation for these hard-core point processes code can be found here:
https://github.com/hpaulkeeler/DetPoisson_MATLAB/blob/master/SubsetGenerate.m
Thank you very much
Hello, I had some thoughts about using this planar point generation method and wanted to adapt it to accommodate for a fix number of final total nodes.
Adding (removing) a fix amount of daughter points for each parent point if there are to few (too many) total points seemed to me like the most straight forward idea.
An example would be that we want a total of 100 nodes. We produce 3 parent points, the number of daughter points for each of them is 34, 45, 37 = 116 total points. We then remove from each set of daughter points 16/3=5.333… points. Rounding it down or up to reach 100 points could finally give the daughter points numbers 29,39,32.
I was wondering if you had any insights on that. A first issue seems to be if there are a lot of points outside our window and we end up with not enough points compared to our objective.
Hi Louis,
Thank you for your email. Sorry for the slow response.
So you want a random number of parents points. But in the end, you want a fixed number, say n, daughter points?
One way to do that is as follows:
1) You (still) simulate a random number N_p of parents points.
2) Then simulate a fixed number n of daughter points.
3) Then for each daughter point, you assign it a label corresponding to its parent. This can just be a random (uniform integer) between 1 and N_p (or between 0 and N_p-1).
4) Then you use the labels to position the daughter points by translating each one in relation to its parent point.
Does that make sense?
I don’t know which language you’re using, but for step 3 you can a standard function for generating a random integer such as this one in Python:
https://numpy.org/doc/stable/reference/random/generated/numpy.random.randint.html
I suppose the problem of truncating points (outside the box) still remains.
You could randomly position these k points again (and again, if necessary). I am not sure if there’s an immediately elegant solution.
Or you do what you suggested, but randomly generate too many points every time. Then truncate based on the simulation window, then randomly thin the remaining k ones by choosing k without replacement. One quick way to do this is to randomly shuffle 1 to m integers, where m is the remaining points inside the window, and then choose the first k integers of the shuffled m integers.
Perhaps this is the better approach.
Sorry about the long response. I started typing my first thoughts, and decided to keep them in the comment.
Does this help?
Paul